Antifragility in the Age of Agentic Code

King Mithridates VI of Pontus had a rather strange daily ritual: he ingested small doses of poison, methodically, over years, to build resistance against assassination by poisoning. In Antifragile, Nicholas Nassim Taleb defines antifragility as a system that doesn’t just resist stress, but improves because of it. Every time King Mithridates ingested a dose of poison, he became more and more tolerant to it.
I’ve been thinking about this concept applied to software engineering, because I think it’s the right mental model for what’s about to happen when codebases are exposed to high volumes of AI-produced code.
Current issues with AI-produced code
Give Claude a non-trivial task. Review the output. Fix the issues, feed them back, and iterate. Depending on complexity, you’ll need at least two or three passes before code smells are gone, what you’ve implemented is satisfactory, and you reach something of minimal acceptable quality.
From this, one thing becomes clear: unsupervised agent work quality is a direct derivative of how many tokens you’re ready to allocate to a task. More review passes, more self-correction, better output. But this doesn’t scale if you have to orchestrate it manually, as you’ll have to stretch thin between multiple tasks in parallel and eventually drop your quality standards.
Human attention hardly scales. AI-assisted development will generate code in volumes that overflow what any team can meaningfully review. The traditional model of “write code, open PR, human reviews” was designed for human-speed output, which I believe most teams have already figured out is hardly sustainable.
There’s a subtler problem, too. The quality of generated code is heavily driven by the quality of the code already in the context window. Good code in context produces decent code; decent code produces mediocre code; bad code compounds into something that actively degrades your codebase. The context is what your LLM is going to reference when writing code, and if that reference is bad, there’s no chance it will produce something better.
So how do you keep producing “good code”? The first obvious step is to reject obviously bad code. The temptation to ship fast and dirty is strong, especially when you can output seemingly working code in minutes and the time required to think about what to build exceeds the time required to build it. This doesn’t work at scale. Don’t mortgage the future for a quick win today.
Some people swear by the “plan-then-implement” approach: write a thorough plan, hand it to Claude Code, and expect it to implement everything properly. It’s a reasonable starting point, but you’ll quickly realize you can’t blindly trust the output. The agent will take suboptimal shortcuts for everything not explicitly specified, and may not even follow the plan correctly.
In my experience, “plan-then-implement” only works well with a tight feedback loop around atomic tasks that fit in about half a context window, where you can trigger reviews automatically, challenging both the plan and its implementation in their context. Waiting for PR reviews on Github for this is too late. Github is a platform made for humans, not for AIs, and your feedback loops should be much tighter.
The upside of these new workflows is that you have the opportunity to build much better systems, much faster, because your ability to capitalize on existing infrastructure through high-quality context ingestion has dramatically increased. In open source ecosystems, you can almost certainly find a library or framework to use as a reference, and produce high-quality code from the start, even if you’re not an expert in the domain.
The remaining question is: how do you build good feedback loops? The first step is to write robust rules that prevent common failure modes from happening in the first place. The second is to build an antifragile system, that not only strives to produce good code, but that learns from new failures and improves itself over time.
Robustness: building the guardrail stack
Robustness is the first layer of defense. It’s Mithridates choosing which poisons to ingest, in what doses, before anyone tries to kill him. In practice, it’s a stack of increasingly specific constraints that block the most common ways agentic code goes wrong.
-
Configure your linter to disallow common LLM shortcuts. This is the most basic layer. LLMs love to take the path of least resistance: inline styles,
anytypes, placeholder values, silent errors, etc. A strict linter config turns these from “things you’ll catch in review” into “things that never reach your branch.” This is your minimum viable robustness, and this should be a must-have; either as post-edit hooks, or as pre-commit hooks. -
Write a concise
CLAUDE.md(orAGENTS.md) that maps your codebase and common workflows. This is what most people get wrong, as they try to stuff too much information into the agents file. Write about where things are defined, what the common workflows are, how concerns are separated. The goal is to give the model enough structural awareness to put code in the right place. Keep it high-signal: every line should earn its place. An overloaded instructions file is worse than none, because it dilutes the important parts. Anything more domain-specific should rather be in a skill file. -
Write domain-specific rules and enforce them via ast-grep or custom linting (e.g. oxlint plugins). LLMs are excellent at producing code that works but violates architectural boundaries. You can write rules that forbid database interactions outside of a
DBservice, ensure domain identifiers are never typed as barestringbut use branded types, block runtime shape-checks on objects that are already strongly typed (LLMs love defensive programming. Catching those will help you divide the LOC produced by 2x). These rules encode decisions that are invisible to a model operating from pattern completion alone. -
Ensure all rules are enforced as priority commands in every workflow. Your linter, ast-grep rules, and guidance must be wired into every path code takes — pre-commit hooks, CI checks, and even better when done as hooks in the harness configuration. If an agent can bypass a rule by running in a different mode, the rule doesn’t exist. The earlier you catch these, the better, as instant feedback can be better leveraged by LLMs. Related references: Plankton
What you’ll notice here, is that this stack doesn’t learn. Every rule in it was written by a human who anticipated a failure mode. That’s necessary, but it’s not sufficient, and antifragility comes from the ability to learn from new mistakes.
From robustness to antifragility
Taleb defines antifragility as the capability of a system to improve itself under adversity. Robustness resists shocks,while antifragility feeds on them.
In the context of agentic development, this means your workflow needs a feedback loop: it must observe its own output, detect patterns of failure, and generate new rules to prevent recurrence. The system should get harder to corrupt over time, not just maintain a fixed level of defense.
This loop operates on a spectrum. On one end, it’s human-triggered: you review a batch of agent output, notice that the model keeps importing a UI primitive directly instead of going through the design system wrapper, and you write an ast-grep rule to block it. The detection was manual, but the enforcement is automated and permanent. That mistake is now structurally impossible.
On the other end, the loop can be partially automated: an agent reviews the diff of another agent’s work, flags patterns that violate architectural boundaries, and proposes rule candidates. A human approves or refines, and the rule enters the stack. The human’s role shifts from detecting issues to validating rules.
Good feedback-loop rules must satisfy two constraints:
- Generic enough to trigger across a broad range of situations.
- Specific enough to avoid false positives. A rule that blocks legitimate code will have your agents end up ignoring warnings and errors, which is worse than having no rule at all.
The rules I mentioned earlier, like enforcing branded types for domain identifiers, didn’t come from a planning session. They came from watching agents make the same category of mistake three or four times, then encoding the fix. Each one started as a code review comment; it became a rule when I realized I was writing the same comment repeatedly.
The moment you notice yourself correcting the same pattern twice, you should be asking whether it can be structurally enforced. If yes, write the rule. The agent will never make that mistake again — and neither will the next agent, or the next developer.
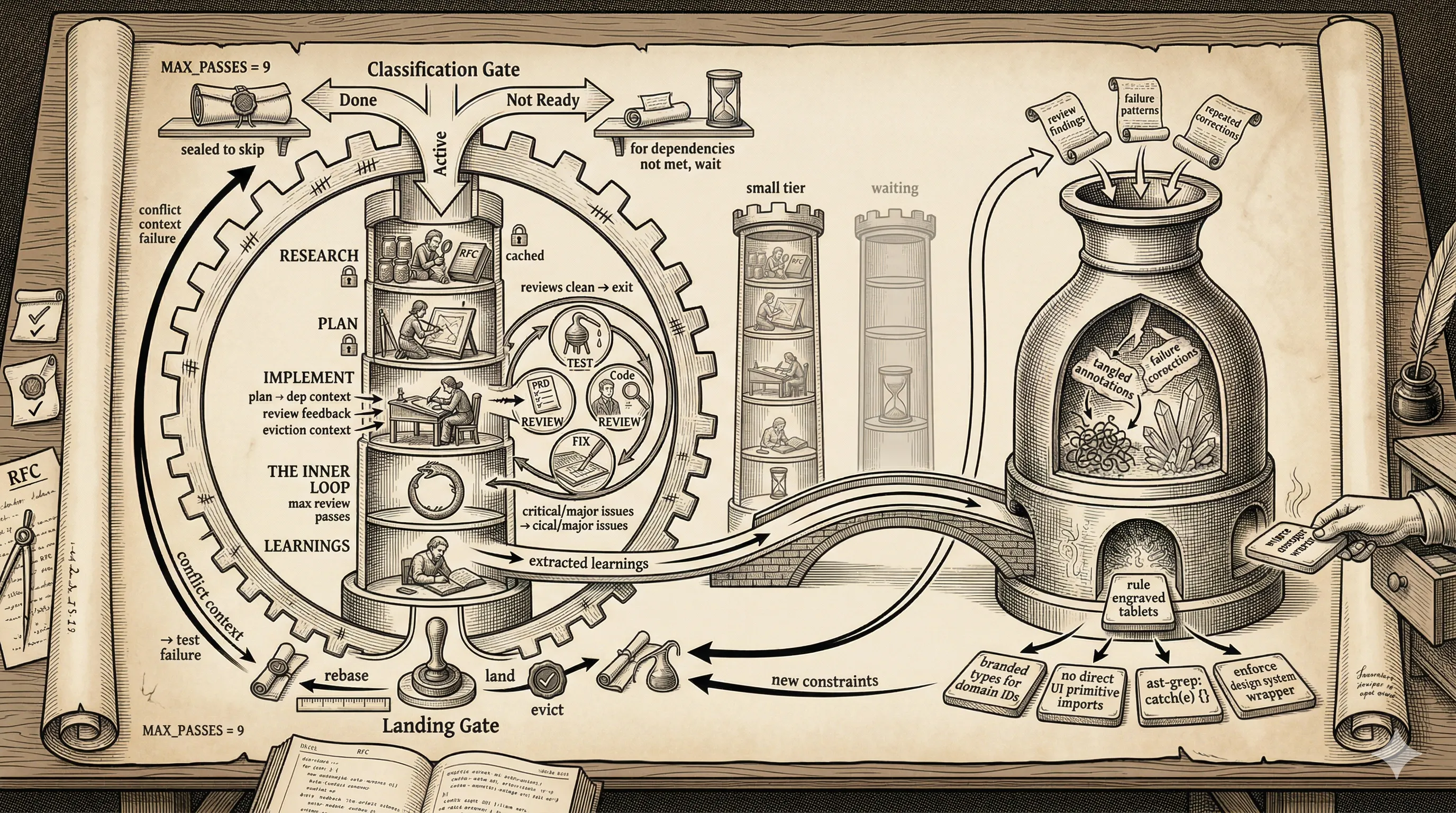
A Concrete Workflow Example
I’ve been pretty vocal about the benefits of using Smithers as an orchestration framework that wraps my CLI coding agents. The main advantage is that it allows me to work completely asynchronously while a task is being implemented, since all code produced by agents will be linted, tested, and reviewed by multiple models before it’s committed to the repository.
This adversarial workflow frees up time to focus on product and system design, while the “grunt” work of the code-review loop is completely automated in the background.
Here’s a concrete illustration of one of my “Implementation” workflows, available on my GitHub. It takes a plan as input, iterates on implementation and review until multiple agents agree on a satisfactory result, and learns from each subsequent review cycle. From these learnings, I can derive new rules that the system enforces, steadily improving the quality of the codebase over time.
The cost of skipping the preparation
As I’ve been experimenting with fully automated development workflows, one thing I can testify to with certainty:
Any shortcut taken at planning time — whether on description of desired state, harness rules to follow, or proper architectural design — is going to be paid for at 10x the price once the slop has crept in.
This is true of software development in general, but agentic workflows amplify it considerably. A human developer who cuts a corner knows they’re cutting a corner. They carry the context of the shortcut and can course-correct later. An agent doesn’t. It will build on the shortcut as if it were the intended design, and every subsequent agent will do the same. The debt compounds silently, and by the time you notice, it’s structural and difficult to fix.
Where this is heading
The endgame isn’t “AI writes code and humans review it”: it doesn’t scale any better than what it replaced. The endgame is codebases where the surface area for novel mistakes shrinks with every iteration
The human’s role shifts from line-by-line inspection to system design, moving up a layer in the abstraction ladder.