The Software Factory

Taylor, Ford, and the birth of industrial process
At the turn of the 20th century, Frederick Taylor introduced Taylorism, a method for organizing factory work around maximizing productivity. Workers followed standardized, timed processes, repeating simple gestures, so that every step of the production chain could be controlled. The core idea was straightforward: separate those who design the work from those who execute it, and standardize every step to eliminate variance. Instead of building a product end to end, each worker specialized in one part of the chain.
Henry Ford took these principles to their logical conclusion with the continuous assembly line and interchangeable parts. Before Ford, assembling a car took roughly 12 hours of artisanal labor. After the assembly line, it dropped to 93 minutes. The workers hadn’t gotten better, but the production process had fundamentally evolved toward more efficient methods.
A century later, software engineering is going through its own transition. Code is becoming easy to produce in high quantities, much like the car in 1910, with industrial methods. The key difference is that the cost of code trends toward zero, because it requires no raw materials, no logistics, no physical constraints. One problem we see is that we’re producing more of it than we need, and not necessarily at optimal quality yet.
The purpose of this article is to introduce the concept of the software factory: a system, inspired by industrial processes, that automates the production of software with controlled processes, checkpoints, and quality assurance.
Software enters its industrial era
With the arrival of coding agents, writing software has become the easy part. Anyone can ask an agent to produce a feature and get a working result in minutes. Code itself is losing its intrinsic value, since its production cost is near zero. What retains value is the production process that surrounds it, and the problem it solves.
This shift is profound because it changes how most developers should think about their work. I experienced this firsthand while implementing Figma designs. I’d steer Claude Code to take screenshots of the mockup, compare them to our app’s render, point out CSS discrepancies one by one, correct them, and loop again. By the third component, I was doing the exact same thing for the third time. That’s when it hit me: what if, instead of doing this work myself, I designed a system capable of doing it autonomously with multimodal models? The idea was to shift reasoning from the unit to the system. You stop thinking “I’ll code this unit” and start thinking “I will design a factory that will produce this result, and the next 50”.
The reason I mentioned Taylor and Ford’s industrial model is because we can see parallels between the two. The division of labor maps to breaking a factory workflow into distinct phases, like research, plan, implement, review, each with its own prompt, inputs, outputs, tools, and validation criteria. The separation between conception and execution carries over directly: the human designs the workflow, the agents execute it. The continuous line is the pipeline that chains tickets automatically.
But a factory can’t run without knowing what it produces. Ford didn’t start assembling cars at random — he knew exactly which model had to come off the line. In software, it’s the same: before building the factory, you need to define the output.
Building Software Factories
To make this concrete, let’s use a running example: converting Figma mockups into code components with their associated Storybook stories. This is a textbook case of repetitive, well-scoped work, exactly the kind a software factory can industrialize. The factory receives a Figma design as input, produces a component and its story, then three control tools validate the result autonomously: the Figma MCP to extract the reference design, Storybook to preview the component across all its states, and agent-browser to run automated visual tests via a headless browser. The remaining work is to automate this process, ensuring all steps run properly and consistently. We’ll come back to this example throughout this section.
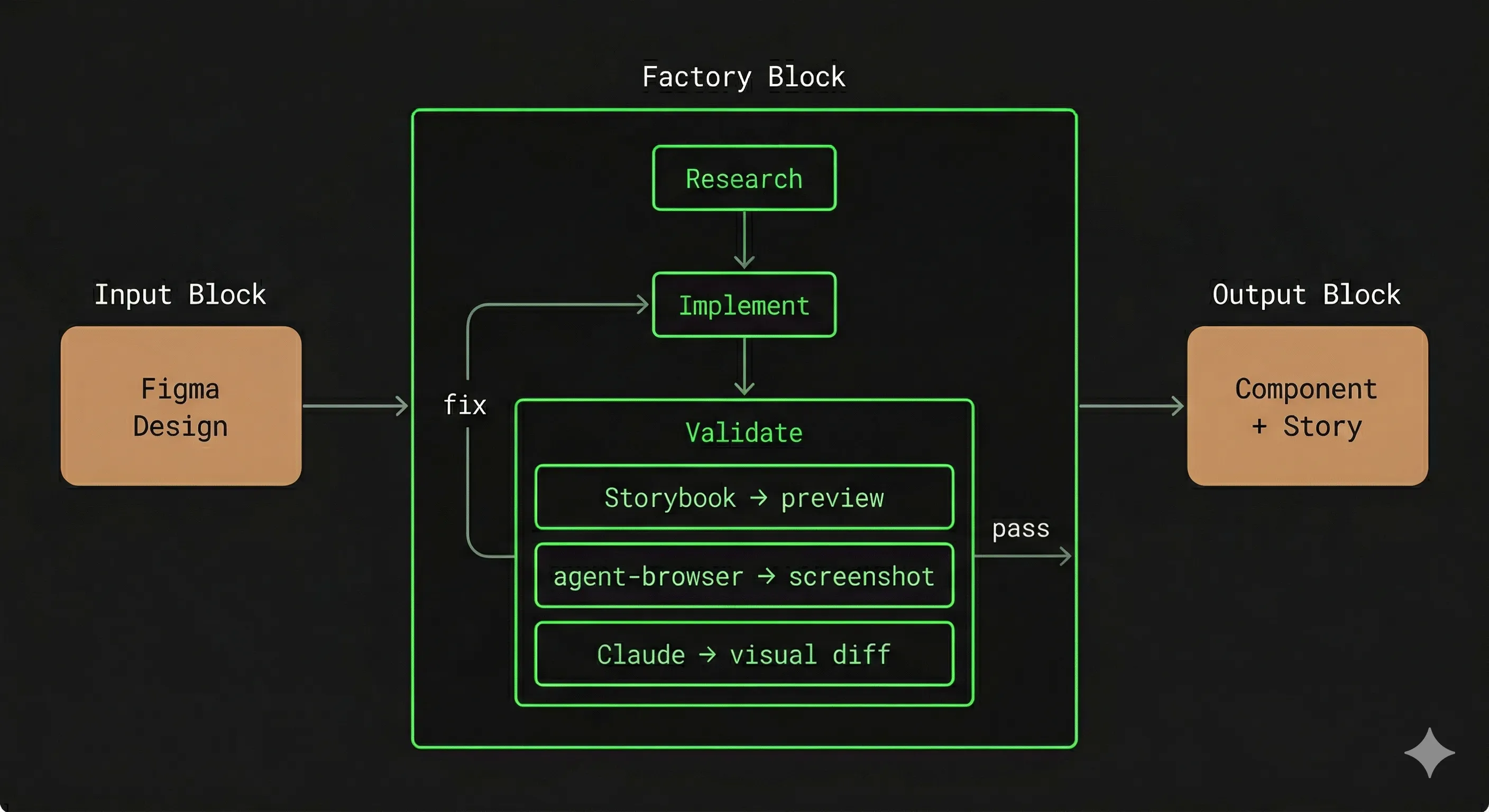
Defining the output
The most tempting trap with agentic code is to dive in without sufficiently defining what you want. But specifying everything would amount to writing the code yourself. You need to find a balance: a specification that defines the desired end state and the deliverables to validate, without dictating the internal steps to get there. You describe the output and the validations, not the route.
This balance sits on a spectrum. At one end, zero tolerance: elements you impose strictly, where no deviation is acceptable. At the other, wide tolerance: elements you delegate entirely to the agent, as long as the final result meets the product need. Too many imposed constraints, and you might as well write the code yourself. Too few, and you get slop: code that technically works but respects neither conventions, nor architecture, nor product intent.
I learned this the hard way working on a project in which I hadn’t locked down the public API tightly enough. The agent produced functional code, but with a public API exploding in every direction, no coherence, and a result that wasn’t pleasant to use as a developer. The impact of the internal code quality is less important, as this is something that can be fixed later in dedicated cycles. Conversely, for a frontend, what you enforce is, for example, conformity to the Figma design, by enforcing a common design system, and validating against the visual result. You delegate the internals to the factory process.
The production process
The idea behind a software factory is something development teams have been doing for a long time. A product manager prepares tickets, a developer analyzes and implements them, another developer reviews them for quality checks, along with some CI checks to automate some part of the process. The common workflow “research → plan → implement → review” is not something new, it’s just a formalization of development processes that have been around for a while.
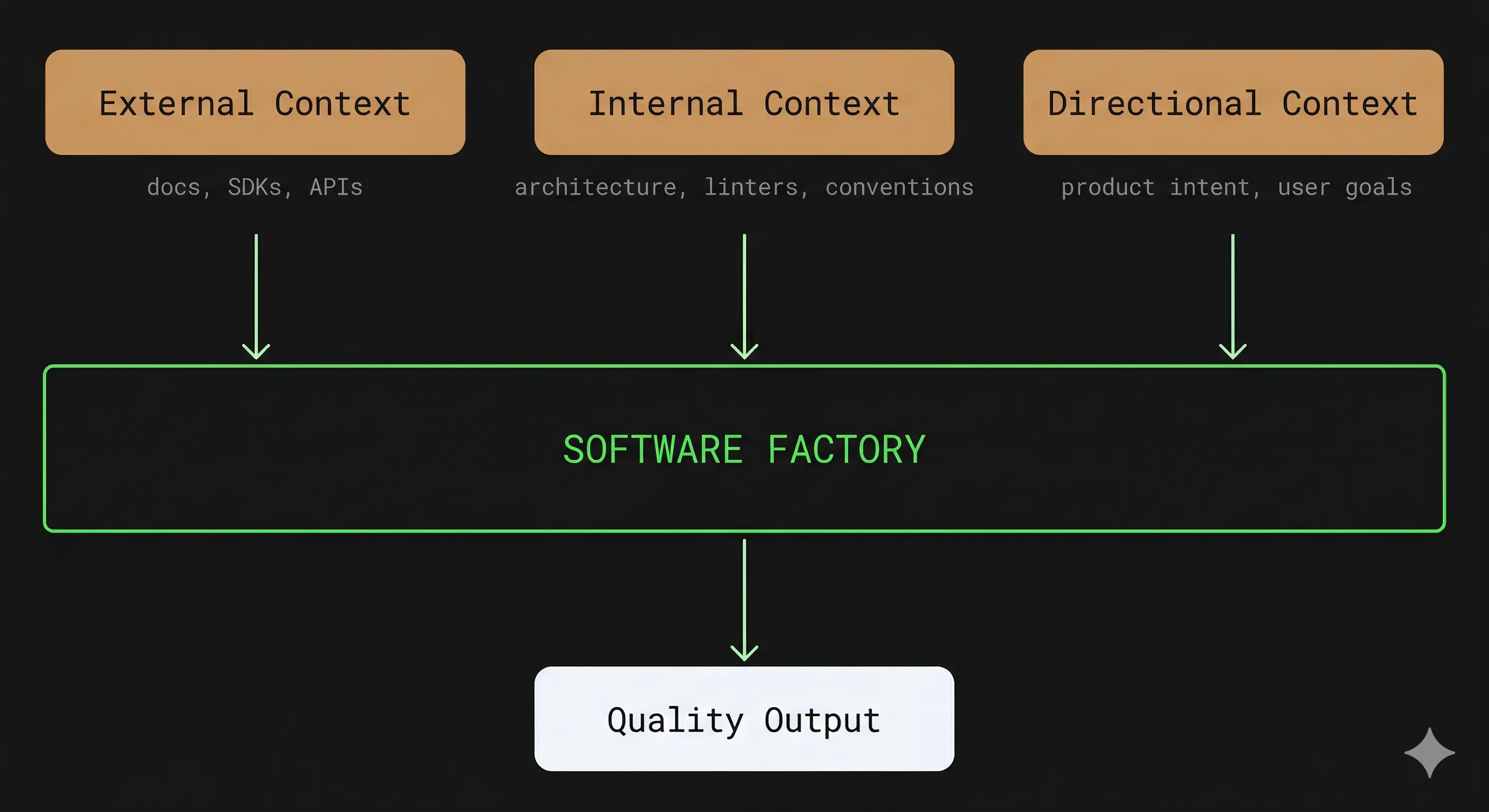
The main bottleneck of a software factory is the input context. An LLM only produces good code if it has the right information, and there are three types of context to manage.
- External context: when working with a library the model doesn’t know well — Effect.ts, a blockchain SDK like Wagmi or Viem, or an internal library — the agent will produce plausible but incorrect code. The solution is to dedicate an upstream research phase, where a sub-agent consults up-to-date documentation and produces a summary injected into the context of subsequent phases.
- Internal context: the codebase’s architecture, proper component isolation, linters, coding best practices — everything that helps the LLM produce code consistent with existing systems.
- Directional context: the intent of the product, the user journey, the business goals — so the LLM can produce code that’s aligned with what you’re actually building.
The quality of the output is the product of the existing foundations, the injected context, and the quality of the factory’s workflows. If any one of the three is weak, the result will be too, regardless of the other two.
In a physical assembly line, there are inspection stations at strategic points in production. In a software factory, this role is played by third-party tools — custom tooling, tests, third-party services, quality checks instructions for an agent, or even human intervention, that can be used to validate an output. In our Figma-to-code example, the three tools introduced earlier (Figma, Storybook, agent-browser) are used together to form a validation loop on the chain, verifying design conformity across all states.
Why would you write a factory when you can just use a coding agent ?
Using a simple coding agent, where the human steers the process manually, is a good way to get started, but shows its limitations quickly when you want to scale the process to a much larger number of tasks. Existing LLMs can’t yet get us the same output quality as hand-crafted code meaning that a human steering an LLM will still be better than an automated flow (and even that is debatable depending on the project / author skills). But the amount of work a human can do in a given time is limited; so the main reason to delegate to a factory is to free up time to work on more important tasks.
An LLM is an amplifier: good code in context produces better code as output; bad code produces worse. This is why you shouldn’t automate too early. The ideal path you want the factory to follow should be walked manually a few times before being automated, as you can’t predict an agent’s behavior from the workflow’s prompts alone, and it requires steering the workflow in the right direction in the beginning. Ideally, you can quantify workflow quality with evals, but that requires significantly more effort. So, ideally, you start by steering a coding agent manually, and then you can automate the process with a factory.
The most insidious trap is quality drift, because it’s invisible at small scale. On the Figma-to-code project mentioned above, I initially implemented components ticket by ticket, without a system ensuring consistency across them. Each component, taken individually, was correct — tests passed, the render matched its mockup. But because the LLM implemented each one in isolation, without a shared design system, colors weren’t perfectly aligned, spacing values varied, typographic conventions drifted. None of these gaps triggered an alert, but put together, the result didn’t form a coherent visual system. Thankfully, factories being very modular, you can add steps to fix these issues, triggered on special conditions, so that you have a good balance between production speed and quality.
Conclusion
The thesis of this article fits in one sentence: code is becoming a commodity; the value is shifting to processes. The work that holds value today is in designing software factories, which means properly thinking about what to produce, and in this regard, structuring workflows, calibrating through dry runs, and setting up validation loops. Writing code itself, as gratifying as it may have been in the past, is no longer the bottleneck, and the time we freed from it can be spent thinking about product.
If this resonates, here’s a concrete starting point. Identify a repetitive task in a project you’re working on, something you do regularly and whose structure is always roughly the same. Break it into steps. Define what you impose and what you delegate, writing this down as a plan file. Run the workflow two or three times by hand. Then, have Claude interview you about the process you just ran, and get Claude to write your first automated workflow using the orchestration framework of your choice: that will be your first software factory.
A tool I’ve been using to write these factories is Smithers. It integrates natively with your preferred Agent CLIs and lets you express your workflows with a simple JSX syntax. I’d also point you to my article on antifragile codebases, which covers the guardrails side of the equation — the rules that prevent code from drifting, and the processes to reinforce them with every detected mistake. The software factory provides the production chain; antifragility provides the immune system. Together, they form a complete system.
I like to think as my software factories as the 21st century version of Charlie Chaplin’s Modern Times in a more human way. Unlike at the time, where the workers were de-humanized through those repetitive gestures, our workers are AI agents, to which we delegate the pesky tasks like writing 50 unit tests. The software engineer instead gets the ability to focus on what matters, freed from the repetitive parts of the job.