La chaîne de montage logiciel

Taylor, Ford, et la naissance du process industriel
Au début du XXe siècle, Frederick Taylor met en place le taylorisme, une méthode d’organisation du travail dans les usines qui vise à maximiser la productivité. Les ouvriers suivaient des processus standardisés et chronométrés, répétant les mêmes gestes simples, afin d’avoir un meilleur contrôle sur chaque étape de la chaîne de production. L’idée principale était simple : séparer ceux qui conçoivent le travail de ceux qui l’exécutent, et standardiser chaque étape afin d’éliminer toute variance. Au lieu de réaliser un produit de bout en bout, chaque ouvrier était spécialisé sur une partie spécifique de la chaîne.
Henry Ford reprend ces principes et les pousse jusqu’à leur conclusion logique avec la chaîne de montage en continu et les pièces interchangeables. Avant Ford, assembler une voiture prenait environ 12 heures de travail artisanal. Après l’introduction de la chaîne de montage, ce temps tombe à 93 minutes. Ce n’est pas que les ouvriers étaient devenus meilleurs, mais simplement que le process de production avait fondamentalement évolué vers des procédés plus efficaces.
Un siècle plus tard, le software engineering vit sa propre transition. Le code est en train de devenir une ressource abondante, à l’image de la voiture en 1910 : on peut le produire en masse avec une méthode industrielle. La grande différence, c’est que le coût du code tend vers zéro — pas de matières premières, pas de logistique, pas de contrainte physique. Le problème, c’est qu’on en produit plus qu’on en a besoin, et pas forcément avec une qualité optimale.
L’objectif de cet article est d’introduire le concept de la software factory : un système, inspiré des processus industriels, qui automatise la production de logiciel avec des processus contrôlés, des postes de contrôle, et de l’assurance qualité.
Le logiciel entre dans son ère industrielle
Avec l’arrivée des agents de code, écrire du logiciel est devenu la partie facile. N’importe qui peut demander à un agent de produire une feature, et obtenir un résultat fonctionnel en quelques minutes. Le code lui-même est en train de perdre sa valeur intrinsèque, puisque son coût de production est quasi nul. Ce qui garde de la valeur, c’est le procédé de production qui l’entoure, et le problème auquel il répond.
Ce changement est profond parce qu’il modifie la façon dont un développeur pense son travail. J’ai vécu ce déclic en implémentant des designs Figma. Je pilotais Claude Code pour prendre les screenshots de la maquette, les comparer au rendu de notre app, pointer les écarts de CSS un par un, corriger et recommencer en boucle. Au troisième composant, je faisais exactement la même chose pour la troisième fois. C’est là que je me suis dit : et si, au lieu de faire ce travail moi-même, je concevais un système capable de le faire de manière autonome avec des modèles multimodaux ? L’idée était de passer du raisonnement à l’unité au raisonnement au système. On ne se dit plus “je vais coder cette unité”. On se dit “je vais concevoir une factory qui va produire ce résultat, et les 50 suivants.”
Les correspondances avec le modèle industriel de Taylor et Ford sont parlantes. La division des tâches trouve son équivalent dans le découpage d’un workflow de factory en phases distinctes — research, plan, implement, review — chacune avec son prompt, ses inputs, ses outputs, ses outils, et ses critères de validation. La séparation conception/exécution se retrouve telle quelle : l’humain conçoit le workflow, les agents l’exécutent. La chaîne en continu, c’est le pipeline qui enchaîne les tickets automatiquement.
Mais une usine ne peut pas tourner sans savoir ce qu’elle produit. Ford ne s’est pas mis à assembler des voitures au hasard — il savait exactement quel modèle devait sortir de la chaîne. Dans le logiciel, c’est la même chose : avant de construire la factory, il faut définir la destination.
Construire des Software Factories
Pour rendre les choses concrètes, prenons un exemple qui servira de fil rouge : convertir des maquettes Figma en composants de code, avec leurs stories Storybook associées. C’est un cas typique de tâche répétitive et bien cadrée — exactement le genre de travail qu’une software factory peut industrialiser. La factory reçoit un design Figma en entrée, produit un composant et sa story, puis trois outils de contrôle valident le résultat de manière autonome : le MCP Figma pour extraire le design de référence, Storybook pour prévisualiser le composant sous tous ses états, et agent-browser pour exécuter des tests visuels automatisés via un headless browser. Le travail restant est d’automatiser ce processus, en s’assurant que toutes les étapes s’exécutent correctement et de manière cohérente. On reviendra sur cet exemple tout au long de cette section.
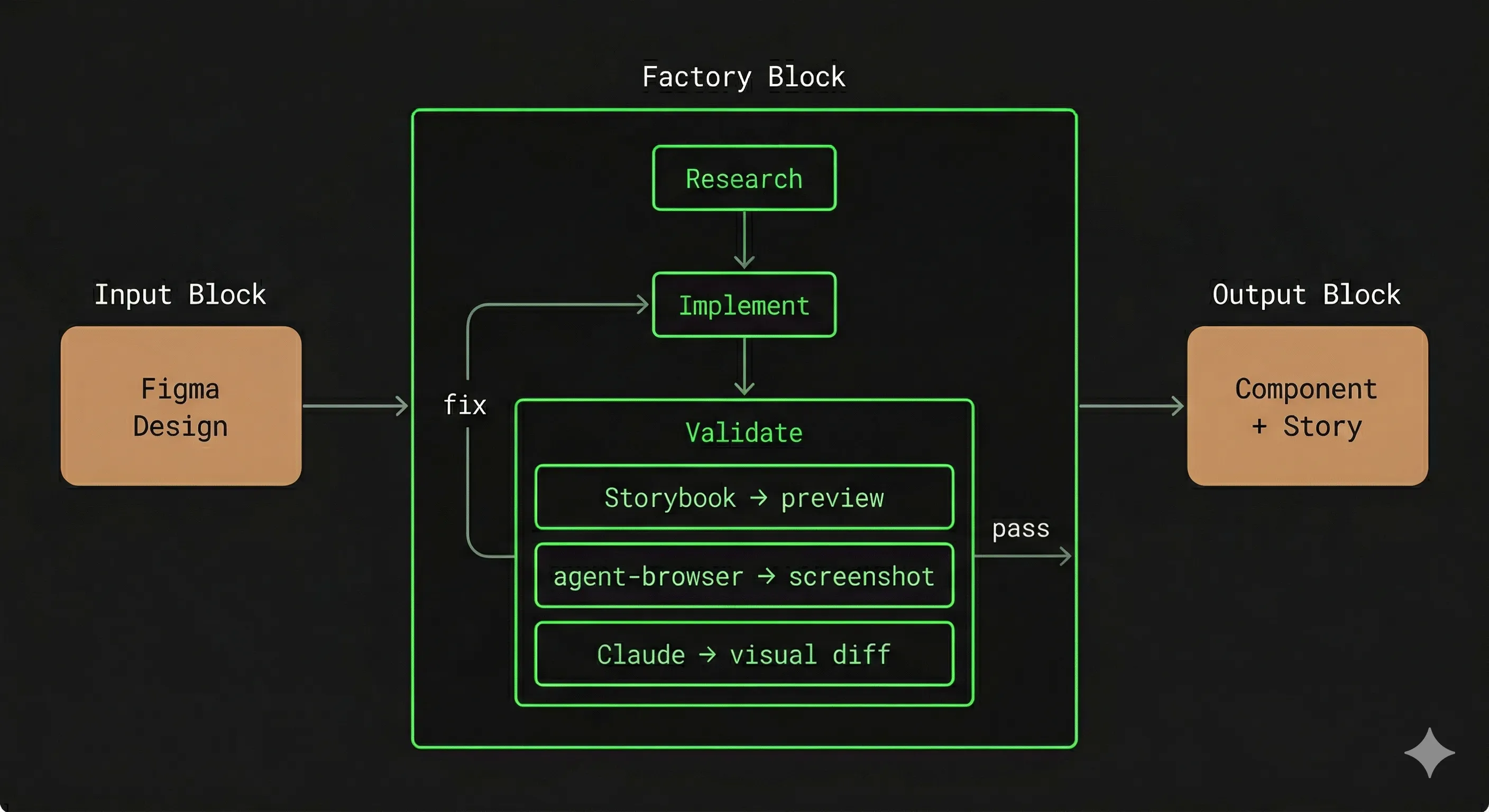
Définir la destination
Le piège le plus tentant avec l’agentic code, c’est de se lancer sans avoir suffisamment défini ce qu’on veut obtenir. Mais tout spécifier reviendrait à écrire le code soi-même. Il faut trouver un point d’équilibre : une spécification qui définit l’état final souhaité et les livrables à valider, sans dicter les étapes internes pour y arriver. On décrit la destination et les validations, pas l’itinéraire.
Ce point d’équilibre se situe sur un spectre. À une extrémité, la tolérance zéro : les éléments que l’on impose strictement, où aucune déviation n’est acceptable. À l’autre, la tolérance large : les éléments qu’on délègue entièrement à l’agent, tant que le résultat final remplit le besoin produit. Trop de contraintes imposées, et autant écrire le code soi-même. Pas assez, et on obtient du slop : du code qui fonctionne techniquement mais qui ne respecte ni les conventions, ni l’architecture, ni l’intention du produit.
J’ai appris ça à mes dépens en travaillant sur un SDK. Je n’avais pas suffisamment verrouillé l’API publique — les exports, la surface exposée aux consommateurs. L’agent a produit du code fonctionnel, mais avec trop d’exports, une API qui explosait dans tous les sens, et un résultat qui n’était pas agréable à utiliser pour un développeur. Le code interne n’était pas génial non plus, mais l’impact est moindre, parce qu’on peut toujours corriger. À l’inverse, pour un frontend, ce qu’on impose c’est par exemple la conformité au design Figma, en imposant un design system commun, et en validant contre le résultat visuel. On délègue les détails internes à la factory.
Le procédé de production
L’idée derrière une software factory, c’est quelque chose que les équipes de développement font déjà depuis longtemps. Un product manager prépare des tickets, un développeur les analyse et les implémente, un autre développeur les review pour des contrôles qualité, avec en parallèle des checks CI pour automatiser une partie du processus. La structure commune utilisée par les gens de l’IA — “research → plan → implement → review” — n’a rien de nouveau, c’est simplement la formalisation de processus de développement qui existent depuis longtemps.
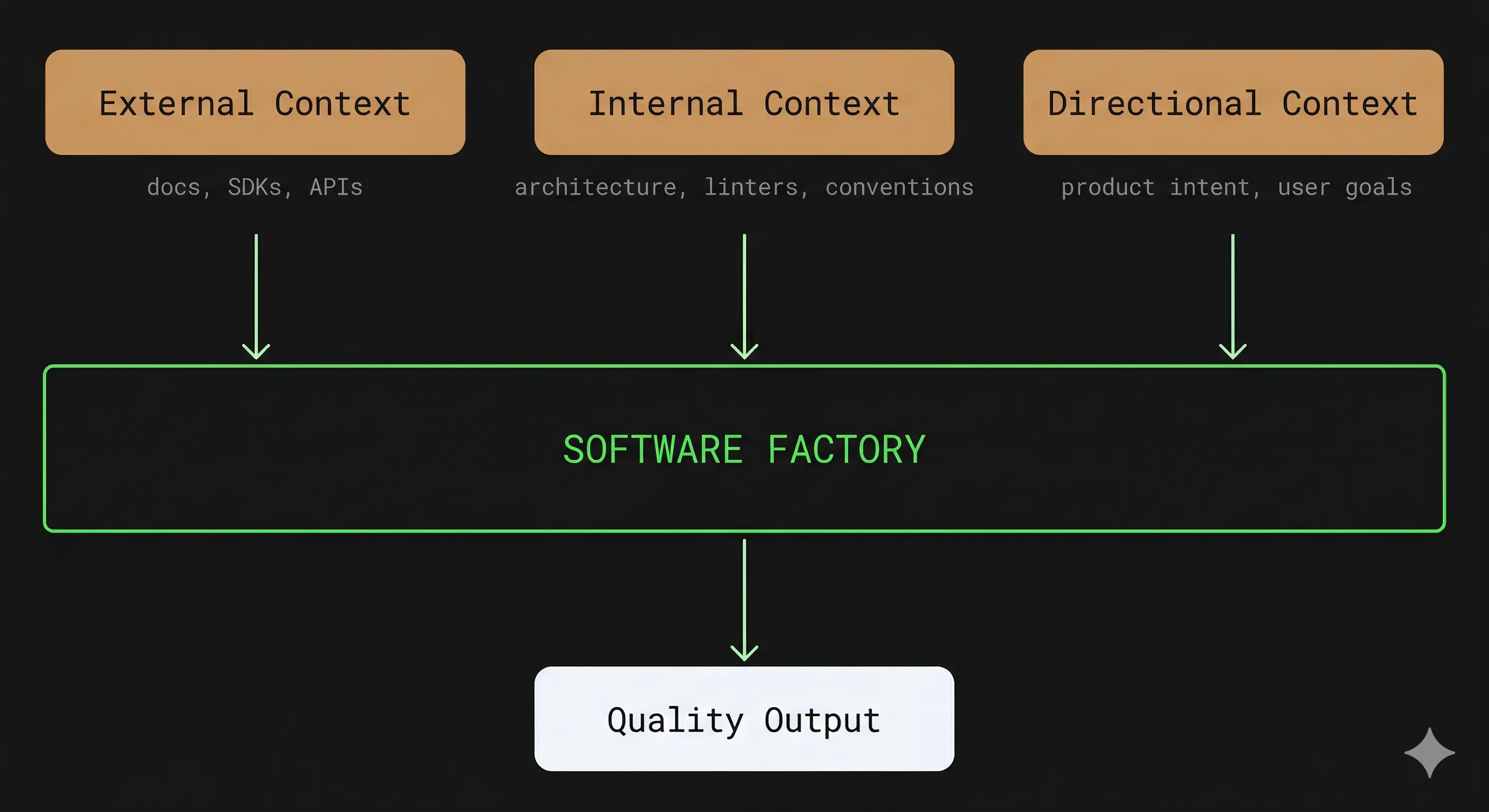
Le goulot d’étranglement principal d’une factory, c’est le contexte. Un LLM ne produit du bon code que s’il dispose des bonnes informations, et il y a trois types de contexte à gérer.
- Le contexte externe : quand on travaille avec une librairie que le modèle ne connaît pas bien — Effect.ts, un SDK blockchain comme Wagmi ou Viem, ou une librairie interne —, l’agent va produire du code plausible mais incorrect. La solution est de dédier une phase de recherche en amont, où un sous-agent consulte la documentation à jour et produit un résumé injecté dans le contexte des phases suivantes.
- Le contexte interne : l’architecture de la codebase, la bonne isolation des composants, les linters, les bonnes pratiques de code — qui donnent au LLM les informations dont il a besoin pour produire du code cohérent avec les systèmes existants.
- Le contexte directionnel : l’intention produit, le parcours utilisateur, les objectifs business — qui donnent au LLM les informations dont il a besoin pour produire du code aligné avec les objectifs du produit.
La qualité de l’output est le produit des fondations existantes, du contexte injecté, et de la qualité des workflows de la factory. Si l’un des trois facteurs est faible, le résultat l’est aussi, indépendamment de la qualité des deux autres.
Les postes de contrôle
Dans une chaîne de montage physique, il y a des stations d’inspection à des points stratégiques de la production. Dans une software factory, ce rôle est joué par des outils tiers — de l’outillage custom, des tests, des services tiers, des instructions spécifiques pour un agent — qui peuvent être utilisés pour valider un output. Dans notre exemple Figma-to-code, les trois outils introduits plus haut (Figma, Storybook, agent-browser) sont utilisés ensemble pour former une boucle de validation sur la chaîne, en vérifiant la conformité au design sous tous ses états.
Il y a une distinction importante entre une software factory automatisée et un simple flow de développement assisté par IA, où l’humain guide l’agent dans la bonne direction. Les LLMs actuels ne peuvent pas encore atteindre la même qualité d’output que les processus industriels, ce qui signifie qu’un humain guidant un LLM fera toujours mieux qu’un flow automatisé. Simplement, la quantité de travail qu’un humain peut fournir dans un temps donné est limitée ; la raison principale de déléguer à une factory est de libérer du temps pour travailler sur des tâches plus importantes.
Un LLM est un amplificateur : du bon code en contexte donne du meilleur code en sortie, du mauvais code donne du pire. C’est pour cette raison qu’il ne faut pas automatiser trop vite. Le chemin idéal qu’on veut que la factory suive doit être parcouru manuellement quelques fois avant d’être automatisé, car on ne peut pas prédire le comportement d’un agent à partir des seuls prompts du workflow, et cela nécessite de guider le workflow dans la bonne direction au départ. Idéalement, on peut quantifier la qualité des workflows avec des evals, mais cela demande beaucoup plus d’efforts.
Le piège le plus insidieux est la dérive de qualité, parce qu’il est invisible à petite échelle. Sur le projet Figma-to-code mentionné plus haut, j’implémentais au début les composants ticket par ticket, sans avoir mis en place de système assurant la cohérence entre eux. Chaque composant, pris individuellement, était correct, les tests passaient, le rendu était conforme à sa maquette. Mais comme le LLM les implémentait dans leur individualité, sans design system partagé, les couleurs n’étaient pas totalement alignées, les valeurs de spacing variaient, les conventions typographiques dérivaient. Aucun de ces écarts ne déclenchait une alerte, mais mis bout à bout, le résultat ne s’inscrivait pas dans un système visuel cohérent.
Conclusion
La thèse de cet article tient en une phrase : le code est en train de devenir un commodity, la valeur se déplace vers les processus. Le travail qui a de la valeur aujourd’hui est dans la conception de software factories, c’est-à-dire bien réfléchir à ce qu’on produit, et à cet égard, structurer les workflows, calibrer par des dry runs, et mettre en place des boucles de validation. L’écriture du code elle-même, aussi gratifiante qu’elle ait pu l’être par le passé, n’est plus le goulot d’étranglement.
Ce parallèle avec les processus industriels invite une objection familière. La séparation entre conception et exécution, appliquée à des personnes, est une forme de déshumanisation du travail, bien illustrée dans Les Temps Modernes de Charlie Chaplin. Mais cette critique repose sur une prémisse spécifique : que les exécutants sont des êtres humains. Quand les exécutants sont des agents IA, la prémisse disparaît, et avec elle l’essentiel de l’objection : personne ne plaint un LLM qui écrit son 50e test unitaire. Au contraire : le développeur retrouve sa créativité et la possibilité de se concentrer sur les tâches qui comptent, en s’affranchissant de la partie répétitive.
Si l’idée vous parle, voici un point de départ concret. Identifiez une tâche répétitive dans un projet sur lequel vous travaillez, quelque chose que vous faites régulièrement et dont la structure est toujours à peu près la même. Décomposez-la en étapes. Définissez ce que vous imposez et ce que vous déléguez, en l’écrivant dans un fichier de plan. Faites tourner le workflow deux ou trois fois à la main. Puis automatisez. Ensuite, faites-vous interviewer par claude sur le processus à mettre en place, et faites-lui écrire votre premier workflow avec le framework d’orchestration de votre choix : ce sera votre première software factory.
Comme outil pour implémenter ces factories, j’utilise Smithers. Il s’intègre nativement avec vos Agent CLI préférées, et vous permet d’exprimer vos workflows avec une syntaxe JSX simple. Je vous renvoie également à mon article sur les codebases antifragiles, qui couvre l’autre versant de l’équation — les règles qui empêchent le code de dériver, et les procédés pour les renforcer avec chaque erreur détectée. La software factory fournit la chaîne de production ; l’antifragilité fournit le système immunitaire. Ensemble, ils forment un système complet.